Meathill 的技术与日常
-

Solidity/Rust 实战 — Web3 开发共学活动
感谢赞助商 HackQuest.io 委托我发布本条消息。 Solidity/Rust 共学营信息清单 关于 …
-

鸣谢各位老板舰长赞助商
想来想去,决定开个页面用来供奉各位支持过我的老板。 赞助我,让我贡献更多内容吧! 欢迎在 GitHub 上赞助…
-

欢迎欢迎
欢迎来到我的博客,我是 Meathill,想了解我可以点 关于我。 除了程序员,我还是个兴趣使然的 Web 开…
-

【代友招聘】【成都】Web3 教学网站 后端工程师
Hackquest.io 是我长期关注并辅佐的一家专注于 Web3 教学的网站的。他们由一群很有热情的年轻人组…
-

系列视频制作中:Next.js 全栈开发每日一签网站
之前的几个系列基本都连载完毕。前些天开了一个新坑:全栈架构师系列。但是这个系列比较难录:讲得深,应用场景就窄,…
-

记一次不成功的数据库搬家
我这个博客始建于 2011 年,当时我从 ZOL 离职,表达欲旺盛的我,希望找个地方继续写博客,于是就买了台集…
-
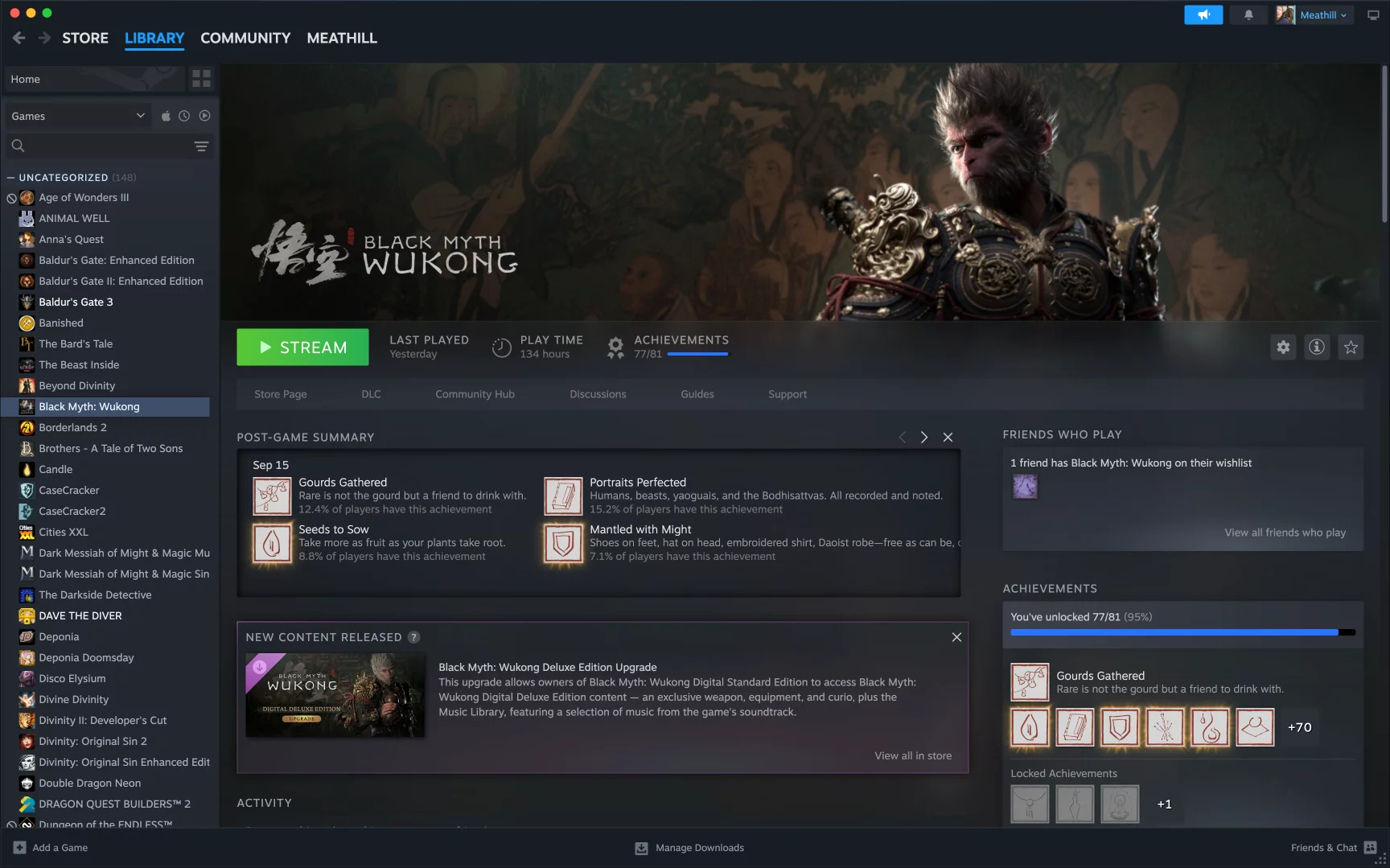
聊聊黑神话:悟空
今天吃过晚饭,禁字诀+救命毫毛战胜大圣残躯,完成二周目。开篇名义,对我来说,黑神话:悟空是今年最佳,甚至 10…
-
【转载】Ilya Sutskever 的 Prompt tips
在 X 上看到这个分享,不得不说,Ilya 真是技术宅,发的图片,还是糊的…… 用 macOS 的文字识别摘下…
-
【视频】接单小故事:关于主人翁意识,主动承担责任。只有大家都靠谱,才会有好结果。
本来想周末写技术文章的,但是由于苦攻《黑神话:悟空》,加上最近几周开始尝试用 React Native + E…
-

2024 中国大陆搭建 React Native 开发环境
我从 Web 前端做起,后来发展到全栈,至今十几年。我觉得大陆的网络环境对 Web 开发还算比较友好,除去 G…
-

【自招】工读生一名,帮我剪视频,未来希望能一起写代码
其实我今年年初就有这个想法了,一直拖着没搞,现在也不敢说是想清楚了,但是觉得必须迈出一步,后面才能更好的收集信…
-

解决跨时区 Nuxt SSR 导致的页面离奇 Bug
打开后台一看,如果本周再不写博客,就三周没更了,还是抽点时间分享点东西吧。今天结合近期解决的问题,分享一下出海…
-

搬家记:从 Vercel 到 Cloudflare(Nuxt 项目x2)
月底的时候,收到 Vercel 的邮件,提示我账号内有一些额度用量已经消耗 50%。我没在意,心想反正月底,马…
- 【代友招聘】【成都】Web3 教学网站 后端工程师Hackquest.io 是我长期关注并辅佐的一家专注于 Web3 教学的网站的。他们由一群很有热情的年轻人组……阅读更多:【代友招聘】【成都】Web3 教学网站 后端工程师
- 系列视频制作中:Next.js 全栈开发每日一签网站之前的几个系列基本都连载完毕。前些天开了一个新坑:全栈架构师系列。但是这个系列比较难录:讲得深,应用场景就窄,……阅读更多:系列视频制作中:Next.js 全栈开发每日一签网站
- 记一次不成功的数据库搬家我这个博客始建于 2011 年,当时我从 ZOL 离职,表达欲旺盛的我,希望找个地方继续写博客,于是就买了台集……阅读更多:记一次不成功的数据库搬家
- 聊聊黑神话:悟空今天吃过晚饭,禁字诀+救命毫毛战胜大圣残躯,完成二周目。开篇名义,对我来说,黑神话:悟空是今年最佳,甚至 10……阅读更多:聊聊黑神话:悟空
- 【转载】Ilya Sutskever 的 Prompt tips在 X 上看到这个分享,不得不说,Ilya 真是技术宅,发的图片,还是糊的…… 用 macOS 的文字识别摘下……阅读更多:【转载】Ilya Sutskever 的 Prompt tips